OCR DATA USAGE ON RD
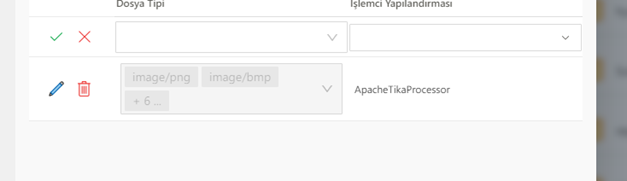
To activate the OCR data, first set the keyname "DocumentManagement.Indexing.Processors" in the configurations table"[ { "Name": "ApacheTikaProcessor", "ProcessorType": 4, "Parameters": { "ServiceUrl": "http://tika.synergy.svc.cluster.local:9998/", "Ocr": true, "OcrLanguage": "eng+tur+deu" }, "FallbackConfiguration": null }, { "Name": "AzureCognitiveComputerVisionOcr", "ProcessorType": 2, "Parameters": { "ClientSecret": "e6aafa07357648de9a357dfa530e4768", "ServiceUrl": "https://westeurope.api.cognitive.microsoft.com/" }, "FallbackConfiguration": null }, { "Name": "Text", "ProcessorType": 1, "Parameters": {}, "FallbackConfiguration": null } ]". On a server basis, if Apache-tika is not installed, this service must also be installed. Then, we define the properties of the file to be uploaded for OCR data in the DM by marking it as in Picture-1. From the RD settings, we need to activate the enable ocr option. We can get the image output containing the text that we uploaded to the RD from the ocr column of the E_ProjeAd ı_FormAd IRD table. See Image-2